
Yesterday Things Were Fine
In a code-only deployment model, rollback is conceptually straightforward: point your runtime at an older artifact and restart. But what happens when your deployment is only partly code, and the rest is metadata records living in a database that mutated in place? This is the reality for platforms built on metadata-driven architectures, and it makes rollback a fundamentally different problem.
Rollback Norms: "Just Redeploy the Old Version"
Rollback in a code-only deployment is a solved problem. The application is an immutable artifact sitting in a registry. Rolling back means pointing runtime at an older tag and restarting. Modern deployment toolkits (blue/green, canary, rolling updates) all assume deployment artifacts are self-contained and stateless. Swap the artifact, restart the process, done. For the stateless compute layer, Kubernetes does this with a single command. Cloud providers offer one-click rollback in their deployment consoles.
It's reasonable that stakeholders bring that mental model into the conversation when they request "rollback capability." It's also incomplete.
The request that prompted this work came from a key partner running a heavily integrated production solution. Their deployment touches a large number of integration points, any one of which could be the source of a regression after a patch. When something breaks at 3 AM, they don't have the luxury of root-cause analysis. They don't know whether the problem is in a changed workflow definition, a modified integration mapping, an updated business rule, or a code change. All they know is that yesterday things were fine, and they need to get back to that state. Now. In a code-only world, that's a five-minute operation. For Nextworld, it's a fundamentally different problem.
Rollback as described in this document requires a dedicated deployment pipeline and database instance. It is only feasible for partners on their own infrastructure and does not apply to partners on shared infrastructure.
When the Product Is the Database
Not all platforms deliver behavior exclusively through code. In a metadata-driven architecture, metadata records are not configuration. They are the application. They define what tables exist, what fields those tables contain, what applications users see, how screens render, and what logic executes when a user takes an action. Workflow orchestration, integration mappings, business rules, validation constraints, lookup values, security policies, AI agent definitions: all metadata records stored in database tables. This is a deliberate architectural choice. Partners extend the platform by authoring their own workflows, applications, and business rules without ever touching the codebase. The platform vendor ships updates to its own metadata alongside code, and both land in the same deployment. Three distinct authors (platform, Nextworld Applications, and partner) contribute metadata to the same running system, each layered on the others.
The rollback implication is immediate. Code artifacts are immutable and versioned; the old image is still in the registry. Metadata deployments are destructive writes. The old state is overwritten the moment the new state lands. There is no prior version sitting in a registry, no tag to roll back to. The artifact that represented "yesterday" was destroyed in the act of deploying "today."
The industry's rollback playbook assumes every deployment artifact has a durable prior version available for restoration. In a metadata-driven platform, that prior version doesn't exist unless it was explicitly captured before the deployment. The conventional model of "select an older artifact" inverts into "manufacture a rollback artifact before you need it."
The Spectrum of Deployed Artifacts
A single deployment may include several distinct artifact types, each with different rollback characteristics. Deployments come in two forms: metadata-only deployments that deliver just a bundle, and full releases that combine code with a bundle.
Code is the familiar case. Frontend assets are delivered as a cumulative zip, backend services as container images. Both are immutable, versioned, and stored in a registry. Rolling back means selecting an earlier artifact. Because both are cumulative, restoring to a prior version reverts everything built and deployed after that point. Conventional rollback works here.
Metadata follows the destructive-write pattern. Rollback requires a pre-captured snapshot of the state that existed before the deployment. But a single patch may touch workflow definitions, screen layouts, logic blocks, integration mappings, and extension points across multiple authoring layers. This is not a simple backup operation. Data copies (reference tables, lookup data) follow the same pattern: delete the existing rows, insert the new ones. Same destructive write, same absence of prior state.
Where it compounds: a single patch may include any combination of these artifact types. Rolling back that patch means coordinating reversals across all of them simultaneously, selecting prior code images and restoring database state from pre-captured snapshots in a single coherent operation.
Manufacturing an Inverse Artifact
In a code-only system, the rollback artifact already exists: the prior image in the registry, the prior zip in the bucket. Nobody had to plan for it because the artifact is a natural byproduct of the build process. Metadata has no equivalent.
To make rollback possible, the system must proactively capture a snapshot of every artifact about to change, before the change is applied. This is the inverse bundle. The incoming bundle declares what it intends to deploy through a set of manifests identifying every metadata record and data copy it will touch. Before applying any of it, the system reads the current state of each target and packages that state into a new bundle, stored alongside the deployment record, ready to be applied if rollback is triggered.
But "capture what's there now" isn't sufficient on its own. The incoming bundle may introduce entirely new artifacts (a new extension, a new workflow definition, a new table definition) that didn't exist in the target environment before. Capturing the prior state of something that didn't previously exist produces nothing. Rollback must also handle deletion: if the original deployment introduced it, the rollback must remove it. This isn't cosmetic cleanup. A table definition artifact left behind after rollback leaves an orphan table, complete with its indexes, constraints, and associated database elements, unreachable through the application but still physically present. An orphaned extension alters the runtime behavior of the element it extends, even if every other artifact has been restored.
There is also a scaling assumption embedded in this approach. A single patch is applied to multiple deployment targets as part of the same operation. The inverse bundle works as a shared rollback artifact only if all targets are in the same state at capture time. Normally they are, because targets receiving the same patch sequence remain aligned. But the moment one target diverges (because it rolled back a previous patch that others did not), its prior state is no longer the same as the rest. A single inverse bundle can no longer represent "prior" for all of them. Per-target inverse bundles would be required, and the bookkeeping cost grows with every divergence. The simplest mitigation is a rule: all targets in a deployment group must remain aligned.
The Human Constraints That Shape the Problem
Maintenance and full functional testing of all integrated systems occurs in a fixed window for this partner: 1 to 6 AM in their time zone. Any service-critical regression introduced by a deployment is expected to be detected and repaired within that window. The request path (partner identifies issue, submits a support ticket, operations receives and acts) runs its course entirely outside of normal working hours.
No subject matter expert is available when rollback is triggered. Nobody can look at the regression and say "this is isolated to a single workflow definition, roll back just that." And the request is non-negotiable. When the partner asks for a rollback, they get it. There is no opportunity to troubleshoot, refine the scope, or propose a less disruptive alternative. "We'd like to investigate first" is not an available response at 3 AM when the partner's operations are impaired.
These constraints collapse the decision space. Any rollback mechanism that requires someone to determine what to roll back is not viable. The only question the operator can answer is: "roll back the last deployment, yes or no?" It is a nuclear option by design, because the conditions under which it is triggered leave no room for precision.
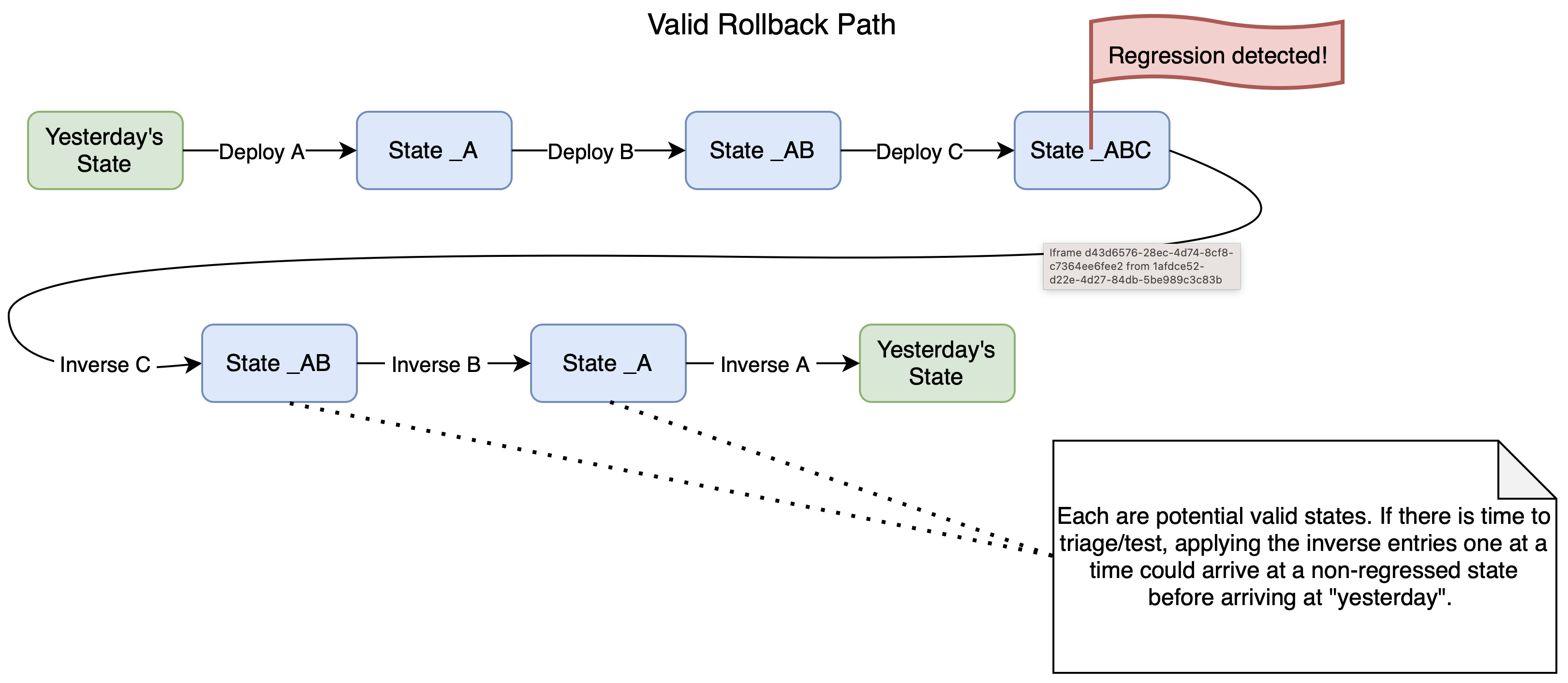
Ordering Constraints: Rollback Is Not Random Access
Code rollback is positional. Because code artifacts are cumulative, each build contains the full application rather than a delta. Selecting any prior version restores a complete, self-consistent state. Want to skip back three versions? Point at that image and deploy.
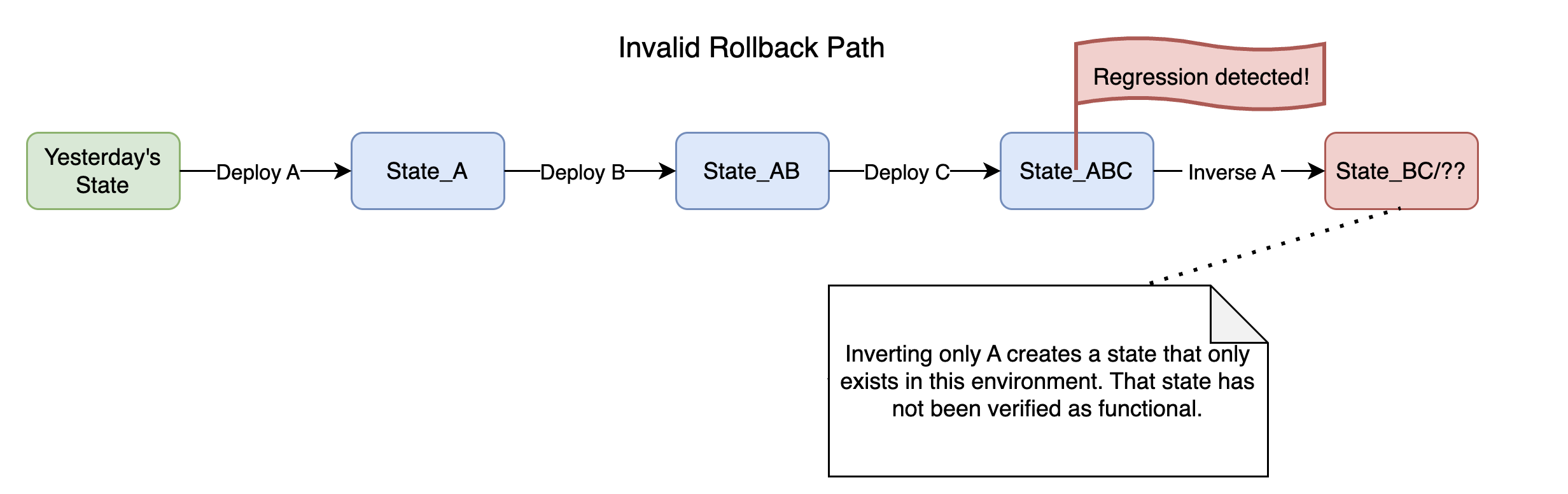
Metadata doesn't work this way. A metadata-only deployment is a delta, not a full snapshot. Its corresponding inverse bundle is also a delta, capturing only the state that the forward bundle displaced. These deltas cannot be applied out of order. If deployment A was followed by B was followed by C, and the regression was introduced by A, rolling back A alone is not possible. The inverse bundle for A restores the state that existed before A was applied, but B and C were applied on top of A's changes. Applying A's inverse into a system that still carries B and C produces a state that never existed and was never tested. To safely reach pre-A, C must be rolled back first, then B, then A. Reverse chronological order, no shortcuts.
Patches that include code and a metadata bundle carry a stricter constraint: all or nothing. A single unit containing platform metadata, NW Apps metadata, frontend code, and backend code was tested and shipped together and must not be separated. There is no smaller rollback target within it. Determining whether a more surgical rollback would suffice requires the kind of root-cause analysis that the operational timeline explicitly does not allow.
Off the Train: The Cost of Divergence
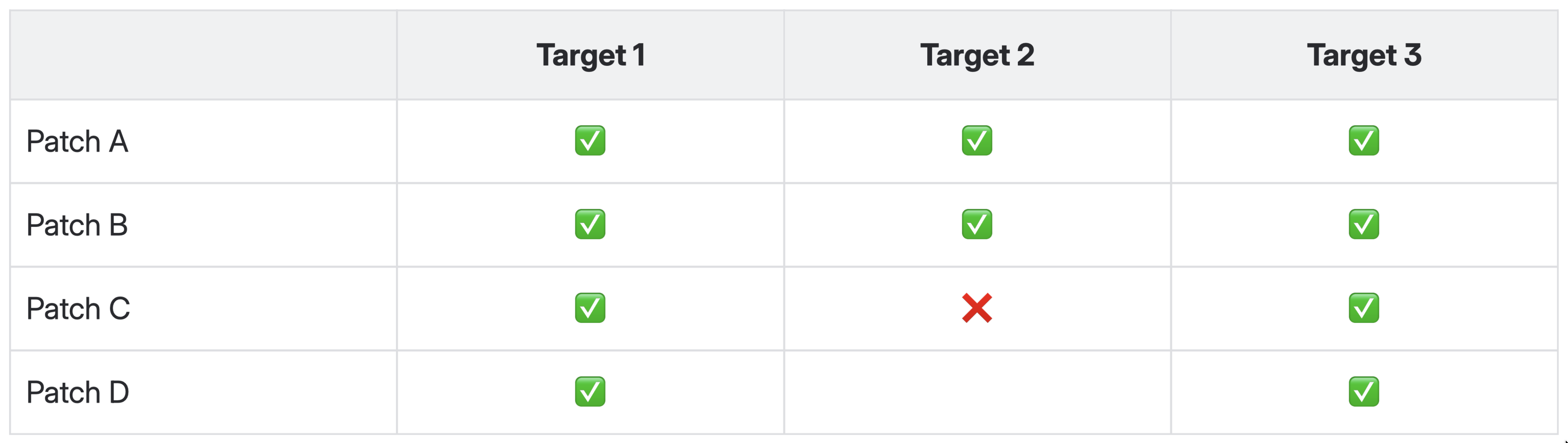
When code-only systems roll back, recovery is seamless. The next deployment overwrites whatever is running, and the rolled-back service rejoins the pipeline automatically.
For a metadata-driven platform, rollback creates divergence. The rolled-back target is now in a state that no other target shares. It missed a deployment, possibly several, that every peer received. It cannot simply receive the next scheduled patch, because that patch was built and tested against the state that includes the changes just reverted. Applying it would reintroduce the problem, or worse, layer new changes on top of an unexpected baseline. It must be taken "off the patch train." No deployments of any kind land until the divergent state is explicitly cleared. This does not resolve itself. It is a hard stop that requires human intervention to lift.
On shared infrastructure, this divergence would not be contained to a single partner. Taking one partner off the patch train would block deployments for every other partner sharing that infrastructure. One partner's decision to roll back cannot prevent others from patching. Dedicated infrastructure is what makes rollback a contained operation.
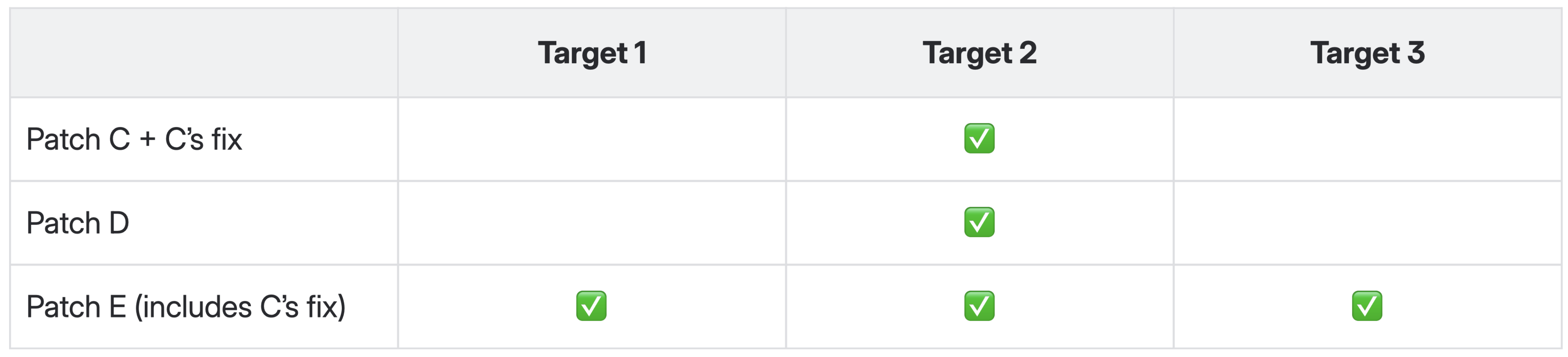
Getting back on the train is the expensive part. The regression that triggered rollback still needs to be understood, and the subject matter expert who was unavailable at 3 AM must now triage the failure. Was it a workflow definition that broke an integration? A business rule that produced incorrect calculations? A table schema change that conflicted with partner-authored metadata? Once the cause is identified and a fix is available, the target must be brought back into alignment with its peers. This is not as simple as reapplying the original deployment with a patch on top. Metadata-only deployments that shipped to other targets while this one was suspended must be applied in order. The fix must be validated against the specific state of the divergent target, not just against the state of targets that were never rolled back. Every step requires evaluation by someone who understands the deployment contents, the partner's configuration, and the interaction between the two.
None of this is automatable in the general case. Operations can execute the mechanical steps, but the judgment calls require engineering context that only SMEs can provide. The 3 AM rollback was fast because it required no judgment. Recovery is slow because it requires all of it.
Regression detected in Target 2 halts its patch cadence, but others continue indefinitely.
Recovery/Realignment centers on Env 2, but is relevant to all.
The Hard Boundary: Business Data Does Not Roll Back
Every section so far has dealt with artifacts that define behavior: code, metadata, data copies. These are the instructions the system follows. Business data is what the system produces when it follows them.
When a workflow definition with an auto-transition to a terminal state is deployed, business data records begin moving to that state immediately. When a business rule recalculates a field, those recalculations are written to live records. When an integration mapping changes how inbound data is processed, the next batch of inbound records reflects the new mapping. These mutations may begin within seconds of deployment, driven by normal system operation. Rollback can revert the definitions, the logic, the mappings. What it cannot do is distinguish which business data mutations were caused by the deployed artifacts and which were the result of unrelated business operations running concurrently.
No better implementation fixes this. Business data is mutated continuously by users, automated processes, integrations, and deployed artifacts, all writing to the same tables, all interleaved in the same transaction logs. Unwinding only the deployment-caused mutations would require causal tracing across every write to every table for the entire duration the artifacts were active. Even if feasible to build, the result would not be trustworthy. Indirect effects cascade through business logic in ways that make it impossible to say with certainty what caused what.
Rollback restores the system's instructions to their prior state. The consequences of those instructions on live business data are permanent and must be addressed through separate remediation.
Rollback Is an Architecture Problem, Not a DevOps Problem
When all you ship is code, rollback lives in runbooks and deployment consoles. The architecture doesn't need to account for it because immutable, versioned artifacts make it an inherent property of the system. Rollback capability comes for free.
Even this is an idealization. Code deployments that include a database schema migration, a changed API contract, or a new message format cannot simply be swapped back without accounting for data written under the new schema. The industry knows this. The difference is one of degree: in a conventional system, state-dependent rollback is an edge case. In a metadata-driven platform, every deployment is a state mutation. The edge case is the entire surface area.
Nothing about rollback comes for free here. The prior state must be proactively captured before every deployment. The capture must account for new artifacts that need to be deleted, not just existing artifacts that need to be restored. The inverse bundle must be stored, associated with the deployment that produced it, and retrievable under operational pressure by someone with no context about what it contained. Ordering constraints must be enforced. The target must be flagged to prevent further deployments from landing on a divergent state. The path back onto the patch train must be managed by humans with domain expertise, one step at a time. None of this emerges naturally from the deployment pipeline. All of it must be designed in: bundle format, deployment orchestration, target management, operational procedures. Rollback is a first-class architectural capability or it doesn't exist.
The industry norms around rollback assume the deployment is a container image or a zip file. Here, the deployment is also thousands of database records that define application behavior, authored by multiple parties, applied destructively, interleaved with business data mutations. The problem is closer to database migration rollback than to code redeployment, but without migration scripts, without a schema versioning tool managing the transitions, and with the additional constraint that the person triggering it has no knowledge of what changed and no time to find out. The partner who asked for this capability was right to ask. "Yesterday things were fine" is a reasonable state to want back. Getting there meant treating rollback as an architectural concern from the start, not an operational procedure bolted on after the fact.

