
Dynamic Agents, Part II: Teaching MCP Tools to Whisper
Last post was about code mode and the three-tool surface that replaced our growing catalog of pre-built MCP tools. Two of those tools, List Libraries and Describe Libraries, work because they follow a simple rule: tell the agent just enough to ask a better question.
That rule has a name: progressive disclosure. And once we’d applied it to libraries, the other half of our MCP server, the metadata side, looked obviously broken by comparison. It was still operating in firehose mode.
This post is about what we did about that.
The problem with handing over everything at once
The MCP server has always exposed a Describe Metadata tool. Its job is to give models the rigid semantic context they need to interact with enterprise data, expressed in OData's Entity Data Model (EDM) via the Common Schema Definition Language (CSDL). The description it returns covers everything the server is bound to.
In its original form, the tool did exactly what its name suggested. You called it with no arguments and got back everything the server knew about, plus the custom EDM vocabulary needed to interpret the annotations. One call, one payload, no decisions for the agent to make.
For a while that was fine. The first Nextworld MCP server was typically bound to a single, focused application: a handful of tables and a dozen logic blocks, which are groups of logical expressions configured to update table data, modify an application's user interface, validate data entry, and test other logic blocks. All that fits easily in context, and the agent reads the dump once and never has to ask again.
The trouble was that the scope kept getting bigger.
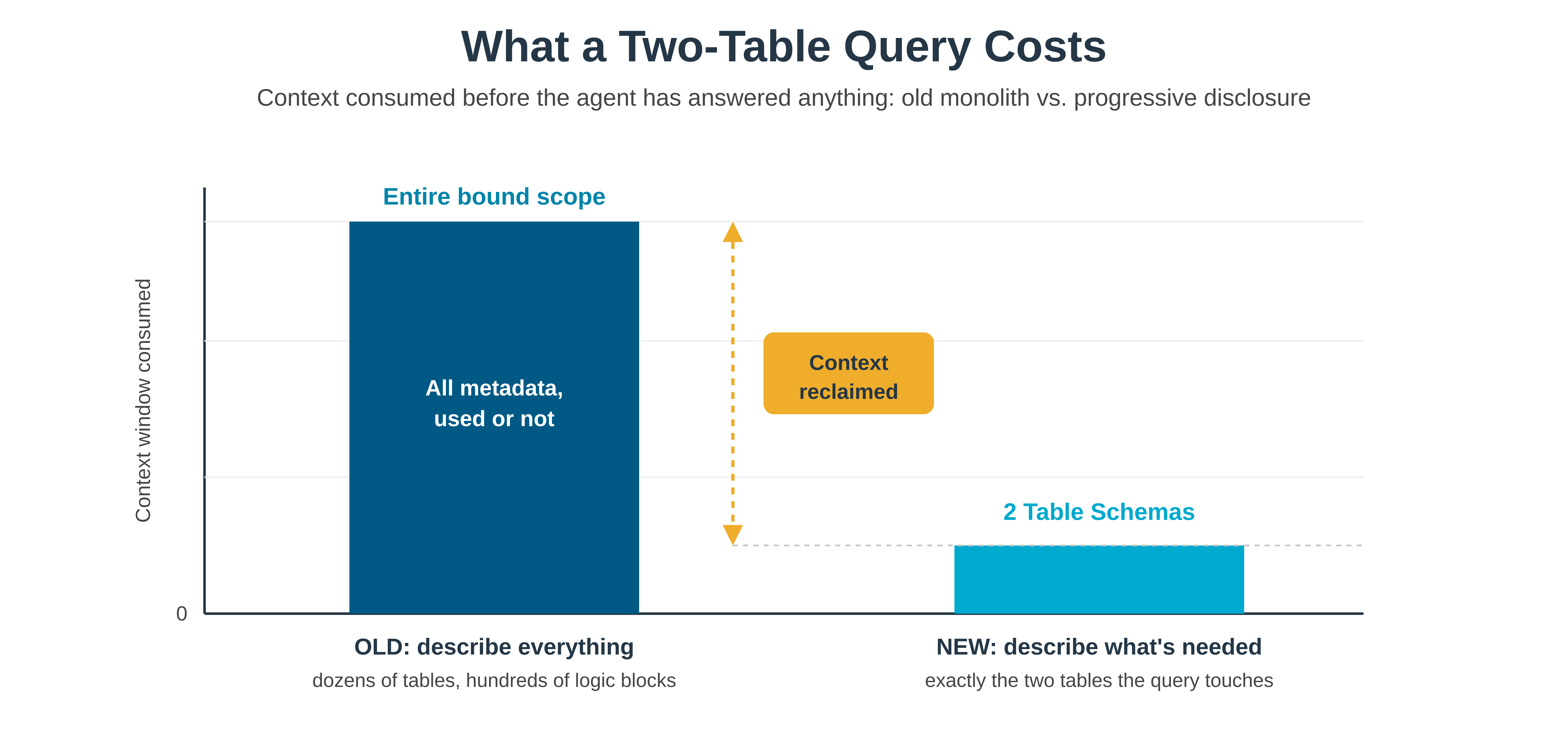
A real Nextworld application like Sales Orders, Procurement, or General Ledger spans dozens of tables and hundreds of logic blocks, with foreign keys reaching across the rest of the platform. And the scope an MCP server is bound to isn’t always a single application anymore. It can also be an MCP bundle, which is a curated list of tables and logic blocks stitching together capabilities from across the platform, or an agentic project, which is a higher-level orchestration that may span multiple applications worth of metadata to serve a single agent. By the time the old “describe everything” call hit one of those, it had already burned a meaningful chunk of the context window or caused an error by exceeding an MCP client’s tool response limit before the user’s first prompt was addressed.
On small applications, this was just wasteful. On larger ones it became painful. For MCP bundles and agentic projects, it was basically a non-starter.
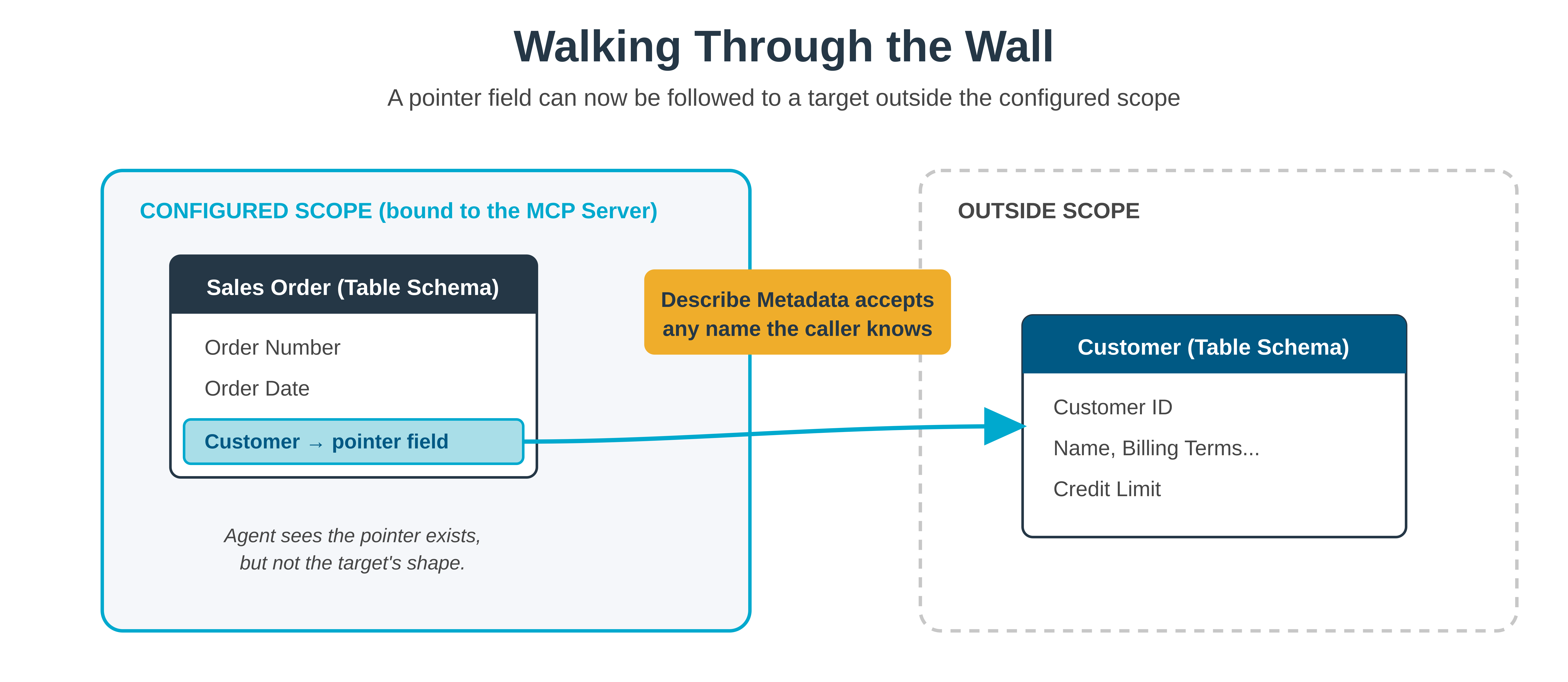
There was a second problem too, less obvious but more limiting. The original describe could only return what the MCP server was bound to. If you had a table schema with a pointer field referencing a target that lived outside the configured scope (and that happens constantly, because real data models cross application boundaries), the agent could see the pointer existed but had no way to ask what was on the other end of it.
The agent was getting more metadata than it needed and was walled off from metadata it did need.
What if the agent only had to load the metadata it was actually about to use?
This was the same shift that produced code mode. The design question shifted from packaging to retrieval: what should the agent be able to ask for at runtime?
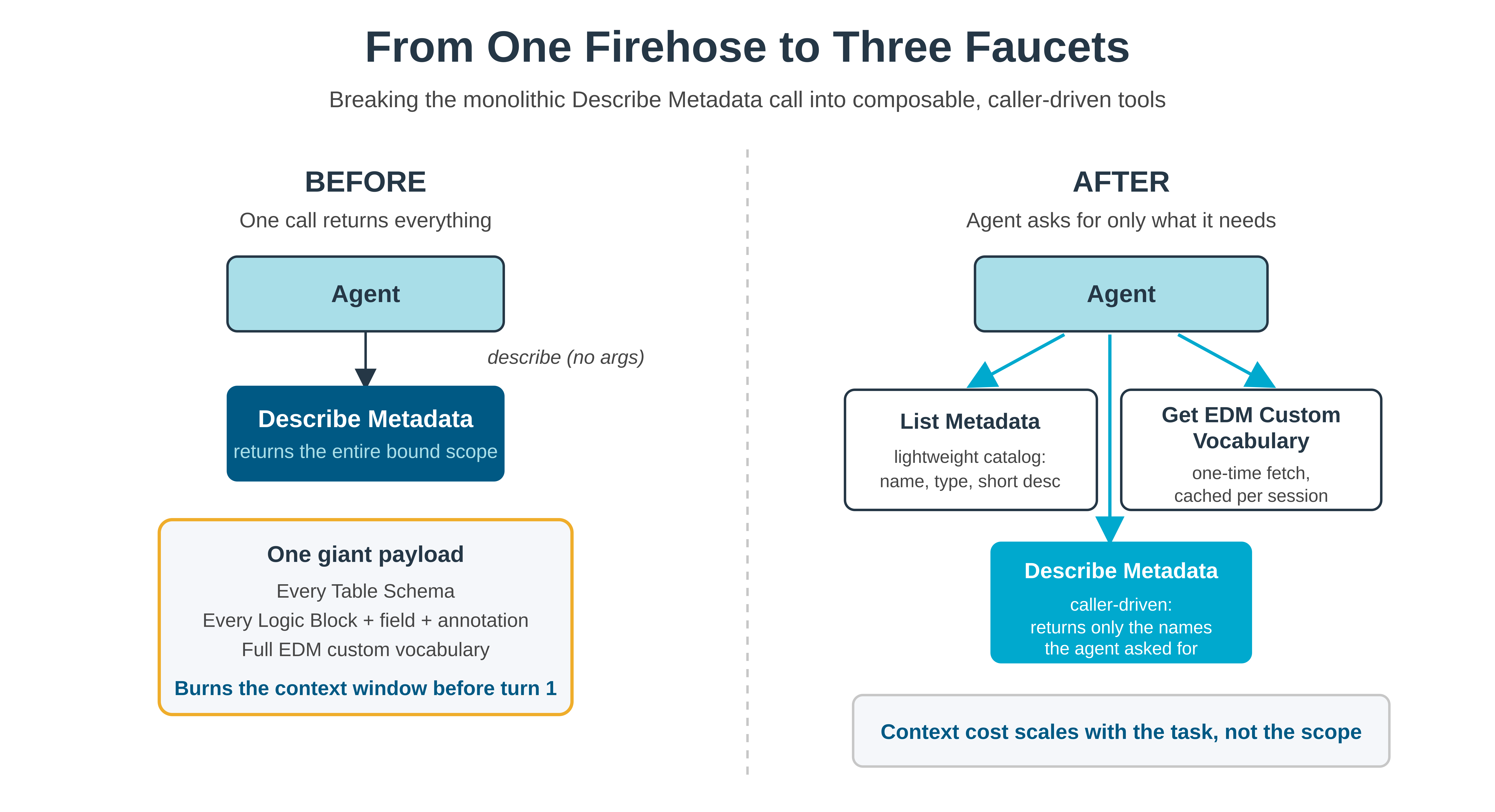
For metadata, that meant breaking the monolith into separate operations: discovery, description, and vocabulary lookup. Each one can be called on its own, held in the context window, and invoked when the agent decides it needs it.
The new shape
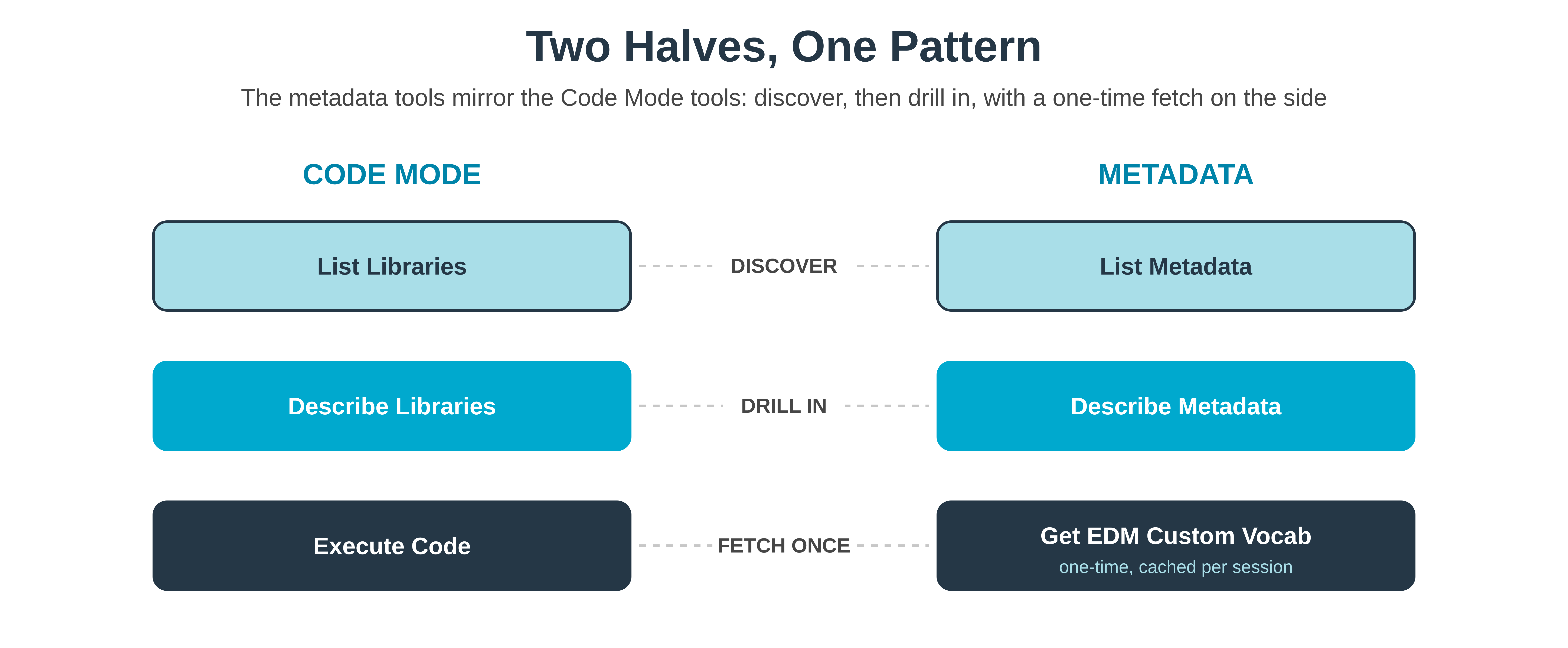
The new surface area has three tools. They mirror the code mode tools intentionally.
List Metadata returns a lightweight catalog of the metadata objects exposed by the MCP server: just a name, a type, and a short description. It's a starting point for discovery. Anything the agent learns about along the way is still describable.
Describe Metadata is now caller-driven. The agent passes an object with one or more of the keys for applications, table schemas, logic blocks, or lookups, each containing an array of names. The server returns only what was asked for. The tool accepts any metadata object name the caller knows, including names that never appeared in List Metadata. When the agent reads a table schema and sees a pointer field referencing some other table, it can call Describe Metadata on that target directly, even if the target lives outside the configured scope.
Get EDM Custom Vocabulary returns the custom OData terms and annotations that appear throughout the describe payloads. It’s a one-time fetch to be stored in the context window.
The one big call became three tools, and the agent decides how deep to go.
Cheaper context, no more dead ends
The biggest thing is that the context window stops getting taxed for metadata the agent isn’t using. A query that touches two table schemas now costs two table schemas of context instead of the entire bound scope. For large applications, that’s a real improvement. For bundles and agentic projects, where the old tool wasn’t usable in the first place, it's what makes the agent usable at all.
Cross-reference traversal also stops being a dead end. The agent sees a foreign key, notices it doesn’t have the target shape, and goes and gets it.
And from the agent's perspective, the two halves of the MCP server now look the same: List Libraries, Describe Libraries, and Execute Code on one side; List Metadata, Describe Metadata, and Get EDM Custom Vocabulary on the other.
The bundling instinct
The instinct to bundle is everywhere in MCP server design. We have the data; the agent will need it, may as well send it all at once. That holds until the payload outgrows the context window, and enterprise data models outgrow it fast.
Code mode taught us the same thing at a different layer of the stack: the cost of a pre-assembled answer grows with the platform, while the cost of primitives grows with the task. At enterprise scale, only the second of those fit in a context window.
That holds up as applications get larger, and as bundles and agentic projects pull more of the platform into a single server. It also benefits from the models improving on their own, since the model is the one deciding what to fetch. Better reasoning means better fetch decisions, and progressive disclosure rewards that.
Where it stands today
The new Describe Metadata is live, along with List Metadata and Get EDM Custom Vocabulary. Existing MCP server deployments are already on it. From the end user’s side, nothing visibly changes. The agent just handles harder questions over larger scopes, whether that's a full application, a bundle, or an agentic project, without losing the thread.
For application developers and platform builders, the change is more substantive. Metadata used to be a monolith that could crowd the agent's other tools out of context. Now it's something the agent can walk around in, at whatever depth and breadth a given task calls for.
Together with code mode, this is what we've been calling Dynamic Agents: the agent gets a place to run code and a way to figure out what to run it against. We'll keep writing about it as it evolves.

